Method Overview
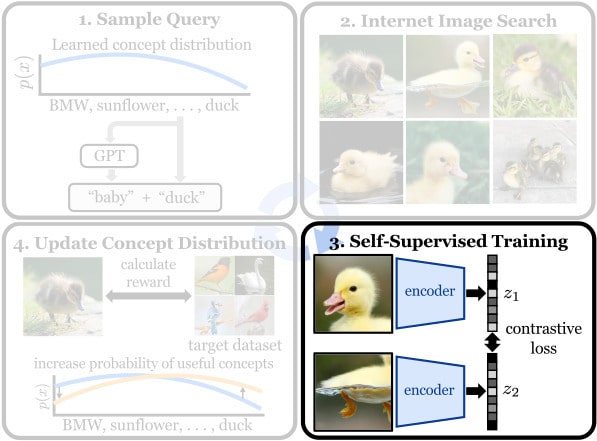
Internet Explorer iteratively repeats 4 steps to find and learn from relevant Internet data. It cycles between searching for images on the Internet with text queries, self-supervised training on downloaded images, determining which images are relevant to the target dataset, and prioritizing what to search for next.
Click on each step to learn more.
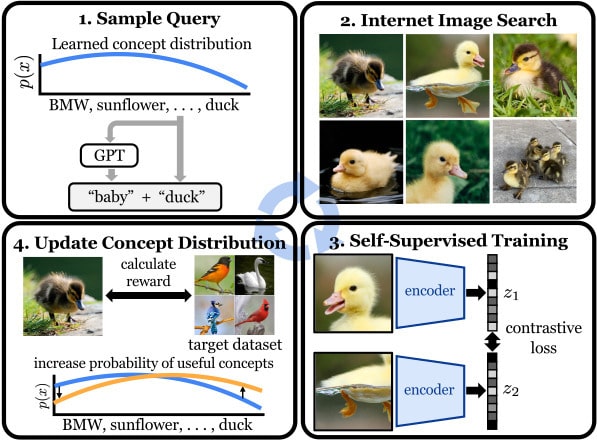
We sample text queries from a concept distribution that is updated after each iteration. This distribution is implicitly defined via our reward estimates for each concept in our vocabulary (Wordnet), and is initialized uniformly. Optionally, we can use a pre-trained language model, like GPT, to help induce more visual diversity in our queries.
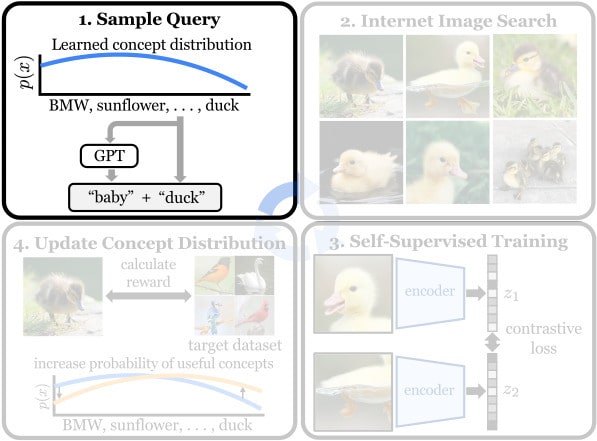
Click outside of the figure to return to the overview.We use the text queries sampled in Step 1 to query text-to-image Search Engines (e.g., Google, Flickr, etc.) for images. We download the top 100 images for each query, and search around 256 queries per iteration. We download these ~25k images in under 5 minutes using parallelism and caching of repeated queries.
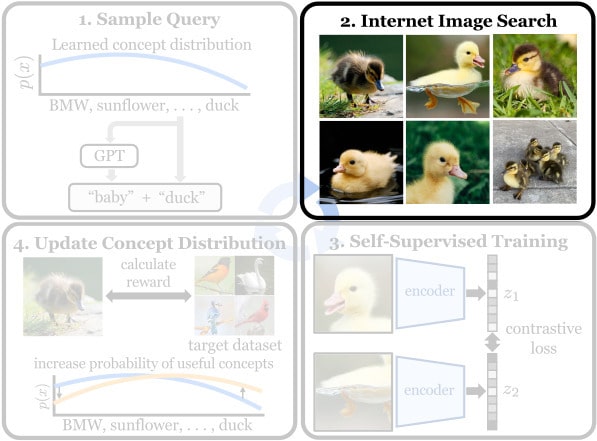
Click outside of the figure to return to the overview.Next we perform self-supervised training on the downloaded images. Any common self-supervised pretext task or algorithm can be used. We train a ResNet-50 using MoCo v3 using a combination of the target dataset, the newly downloaded "candidate" images, and a replay buffer of previously downloaded images that were deemed to be relevant training data.
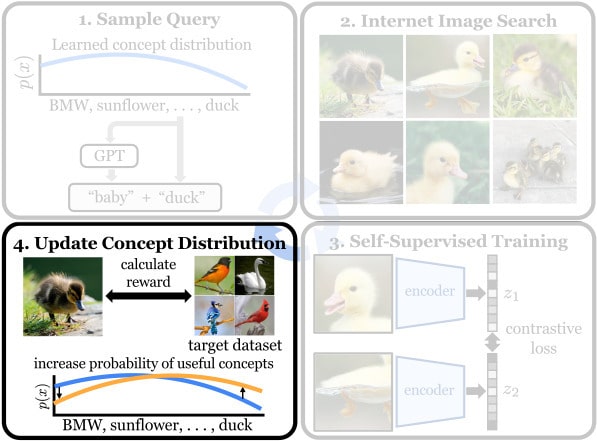
Click outside of the figure to return to the overview.Finally, we update the concept distribution based on a self-supervised relevance reward. The reward for each "candidate" image is its average cosine similarity to its k-nearest neighbors in the target dataset using the current model's feature representations. We then aggregate the image-level rewards to the query-level and fit a regression model using text-embedding features of the queries to predict the rewards for unseen queries in the next iteration.
Click outside of the figure to return to the overview.








